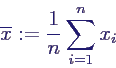Eindimensionale Daten
- Häufigkeitstabelle:
- Bezeichnungen
- n statistische Einheiten, durchnummeriert von 1
bis n
- m verschiedene Merkmalsausprägungen aj,
j = 1 .. m (m ≤ n)
- xi = Ausprägung von X bei Einheit
i
- aj = j-te Ausprägung des Merkmals
- absolute Häufigkeit von Merkmalsausprägung
j
- hj = Anzahl der xi mit xi
= aj
- relative Häufigkeit von Merkmalsausprägung
j
- graphische Darstellung z. B. als Stab-, Balken- oder
Tortendiagramm
- Klassenbildung:
- bei großem m mehrere Ausprägungen zu einer
Klasse zusammenfassen
- bei qualitativen Merkmalen häufig Klasse
für die seltenen Ausprägungen
- bei stetigen Merkmalen üblicherweise durch
Vorgabe von Intervallen
- hj = Anzahl der xi mit
Ausprägung in [cj-1, cj), j =
1, .., m
- auch bei diskreten Merkmalen mit großem m
- Darstellung als Balkendiagramm (Histogramm)
- Balkenfläche ~ hj (nicht
Balkenhöhe)
- Tipps
- möglichst keine unbeschränkten Klassen
an den Enden
- Zahl der Klassen ≤ n
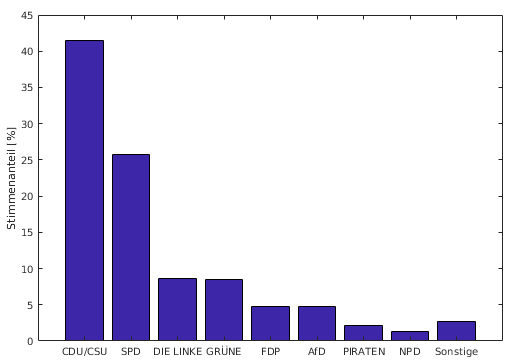
- Beispiel C, Bundestagswahl 2013:
- Daten über Wahlbezirke zusammengefasst (wahl2013.xlsx)
- Tabelle enthält direkt die hj
- gültige Stimmen für 30 Parteien →
m = 30
- Klassenbildung
- Klasse "CDU/CSU"
- Klasse "Sonstige" für fi < 1%
- alle übrigen eine Klasse
- relative Häufigkeiten der Parteien in %
-
| CDU/CSU |
SPD |
DIE LINKE |
GRÜNE |
FDP |
AfD |
PIRATEN |
NPD |
Sonstige |
| 41.54 |
25.73 |
8.59 |
8.45 |
4.76 |
4.70 |
2.19 |
1.28 |
2.74 |
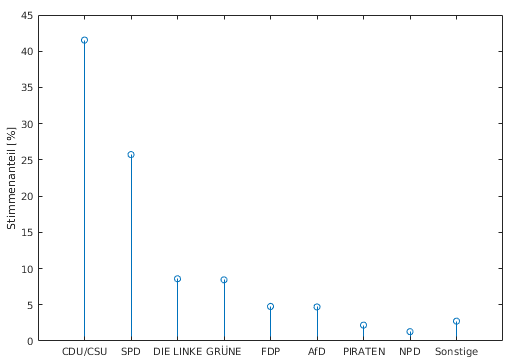
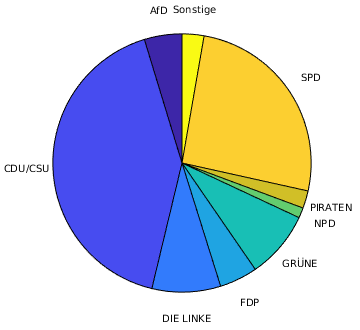
- graphische Darstellungen
- Kennzahlen zur Beschreibung der Lage:
- bei quantitativen Merkmalen Kennzahlen analog zu
denen von Wahrscheinlichkeitsverteilungen
- Mittelwert
- p-Quantil xp (p
∈ [0,1]) teilt die nach Größe sortierten Daten so,
dass Anteil p der Werte links liegt, 1-p rechts; genauer
- Anzahl(xi ≤ xp) ≥ n p
- Anzahl(xi ≥ xp) ≥ n
(1-p)
- xp ist eindeutig ⇔ n p nicht
ganzzahlig
- anschaulich sofort klar für p = 0.5
- bei mehrdeutigem xp wird meist der
Mittelwert der beiden umliegenden Werte benutzt
- wichtige Spezialfälle
- 1. Quartil x1/4
= Q1
- Median x1/2 =
xmed
- 3. Quartil x3/4
= Q3
- Modus oder Modalwert
- Merkmalsausprägung mit der
größten Häufigkeit
- auch für qualitative Merkmale definiert
- Kennzahlen zur Beschreibung der Streuung:
- empirische Varianz
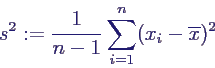
- ähnlich zur Varianz, aber mit Nenner (n-1)
statt n
- gute mathematische Gründe für diese
Definition (s.u.)
- anschaulich: ein Wert wird zur Berechnung des
Mittelwerts "verbraucht"
- entsprechend empirische
Standardabweichung s
- Interquartilsabstand (IQR)
- Spannbreite
- R = xmax - xmin
- mit kleinster/größter Ausprägung
xmin/xmax
- Faustregel für Ausreißer-Kandidaten
- unterer Zaun zu = Q1 - 1.5
dQ
- oberer Zaun zo = Q3 + 1.5 dQ
- Ausreißer: kleiner als zu oder
größer als zo
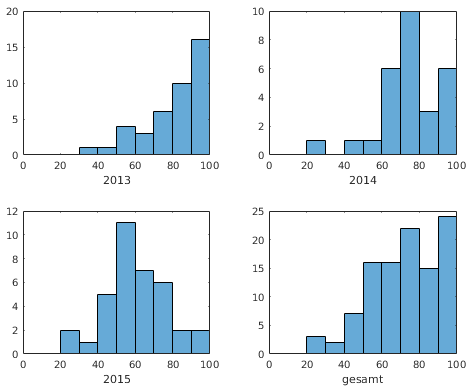
- Beispiel B, Klausuren der Jahrgänge 2013-2015:
- betrachtetes Merkmal: Gesamtprozent, Jahr
- Auswertungen pro Jahr und gesamt
- Histogramme mit 10er-Gruppen
- Ergebnisse
-
| Kennzahl |
2013 |
2014 |
2015 |
gesamt |
mean
|
80.56
|
74.36
|
59.89
|
71.82
|
Q1
|
74.00
|
65.00
|
50.50
|
57.00
|
median
|
83.00
|
72.00
|
57.00
|
72.00
|
Q3
|
93.00
|
88.00
|
70.00
|
89.00
|
| IQR |
19.00 |
23.00 |
19.50 |
32.00 |
s
|
16.70
|
17.65
|
17.15
|
19.19
|
- Grafische Darstellungen:
- Box-Plot visualisiert xmin, Q1,
xmed, Q3, xmax
- Box von Q1 bis Q3
- xmed als rote Querlinie oder Punkt in
der Box
- Linien (Whisker) bis xmin,
xmax
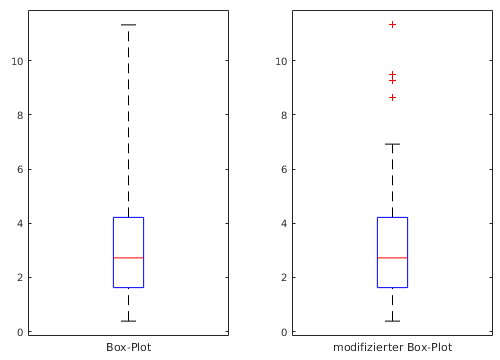
- modifizierter Box-Plot
- Whisker nur bis zum kleinsten/größten
Wert innerhalb [zu, zo]
- Ausreißer als Sterne o.ä. markiert
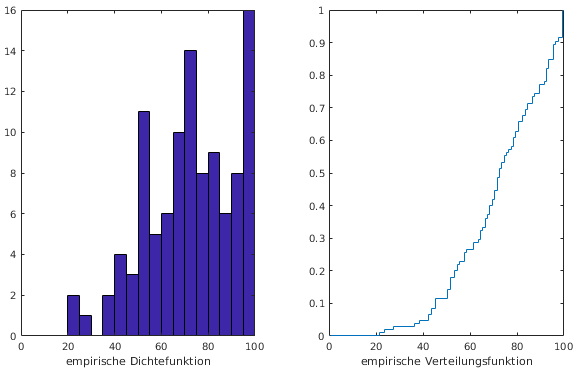
- empirische Verteilungsfunktion
- F(x) = Anteil der Beobachtungen ≤ x
- ganz analog zur kumulativen Verteilungsfunktion
- daraus Quantile leicht ablesbar wegen F(xp)
= p
- empirische Dichtefunktion
- Histogramm mit gleich breiten (aber kleinen)
Intervallen
- sinnvoll bei stetigem Merkmal und vielen Daten
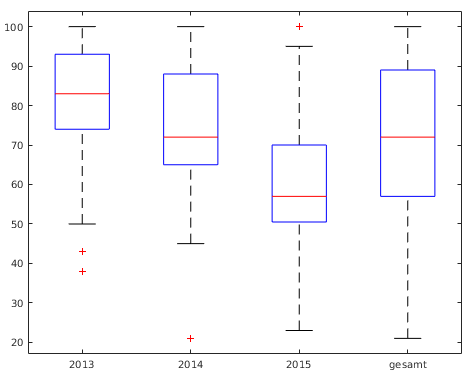
- Beispiel Klausuren
- Box-Plot der
Gesamtprozent-Ergebnisse
- empirische Dichte- und Verteilungsfunktion
- Aufgaben: