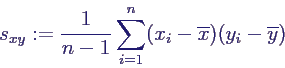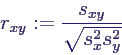Zweidimensionale Daten
- Untersuchung zweidimensionaler Daten:
- an statistischen Einheiten werden jeweils zwei
Merkmale X, Y gemessen
- → Daten sind Zahlenpaare (xi, yi)
- alle 1d-Methoden anwendbar auf Daten xi
bzw. yi
- suchen Zusammenhänge zwischen xi, yi
- meistens Tendenzen (großer Wert für X
kommt häufig mit großem Wert für Y), nicht
funktionale Zusammenhänge
- falls doch funktionaler Zusammenhang besteht
→ Regressionsrechnung
- Darstellung zweidimensionaler Daten:
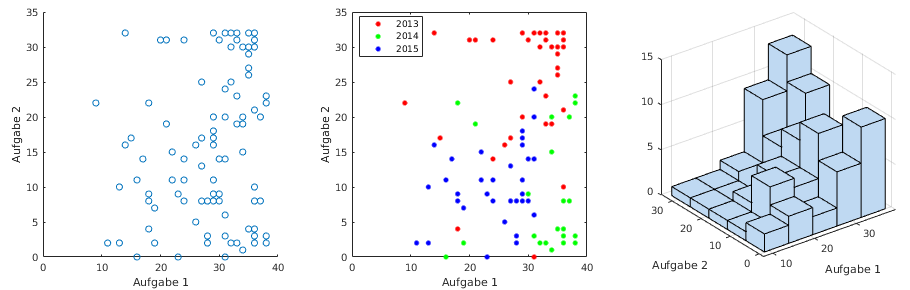
- Streudiagramm (Punktwolke, scatter plot)
- jeder Datensatz wird als Punkt oder Symbol in
x-y-Diagramm aufgetragen
- gibt Überblick über Grundverhalten
- zeigt spezielle Verhältnisse an, z. B.
Bildung mehrerer Cluster
- Streudiagramm mit Gruppenzuordnung
- interessant, wenn Daten in verschiedene Gruppen
zerfallen, z.B. Messreihen, Jahrgänge
- Gruppenzugehörigkeit eines Punkts durch
Farbe oder Symboltyp markiert
- 2d-Histogramm
- Klassenbildung in X und Y, insbesondere durch
Intervalleinteilung
- Anzahl der Datensätze in Klasse KXi
∩ KYj als Balken an Position (i,j)
- Beispiel: Klausurergebnisse in Aufgabe 1 bzw. Aufgabe
2
- Empirische Kovarianz:
- Definition der empirischen Kovarianz sxy
- analog zur Kovarianz bei
Wahrscheinlichkeitsverteilungen
- sxy skalenabhängig, daher
Korrelationskoeffizient rxy
- Beispiel: Klausurergebnisse in Aufgabe 1 bzw. Aufgabe
2
-
| |
2013 |
2014 |
2015 |
gesamt |
| rxy |
0.2256 |
0.1246 |
0.2600 |
0.1952 |
- auffällig: niedriges rxy im Jahr 2014
- Ursache: viele mit gutem Ergebnis in
Aufgabe 1 und schlechtem in Aufgabe 2
- Korrelation ≠ Kausalität:
- Korrelation kann vieles bedeuten
- manchmal wirklich einen kausalen Zusammenhang
- häufig einen kausalen Zusammenhang beider
Größen zu einer dritten, nicht beobachteten
Größe
- eine voreingenommene Auswahl von Daten
- oder einfach Zufall
- Beispiel Störche
- statistische Einheit: deutsche Landkreise und
Städte
- Merkmale: Geburtenrate, Zahl der Störche pro
Fläche
- Korrelation ist hoch: Wo es viele Störche
gibt, werden viele Kinder geboren
- Kausalität ist wohl eher unwahrscheinlich
- Hintergrundgröße: durchschnittliche
Gemeindegröße
- klar: im ländlichen Raum gibt es mehr
Geburten und mehr Störche
- Beispiel Fussball [Maas, Kap. 17]
- Merkmale: Siegtage von Bayern München bzw.
FC Augsburg in der Fußball-Bundeliga-Saison 2012/13
(ausgenommen Spiele gegeneinander)
- Beobachtung: an jedem Tag, an dem Augsburg
gewonnen hat, hat auch München gewonnen
- Kann das Zufall sein? Ja!
- Autor hat unter den Daten nach passendem Verein
gesucht
- Kausalität lässt sich allein aus
statistischer Analyse nicht feststellen!
- Q-Q-Plot:
- graphische Methode zum Vergleich zweier Verteilungen
- haben zwei Datensätze gleiche Verteilung?
- entsprechen Daten eines Datensatzes einer
theoretischen Verteilung?
- genauere (quantitative) Aussagen in der Testtheorie
- Vorgehen
- berechne Quantile xq, yq
für viele Werte von q
- plotte Punkte (xq, yq)
- Auswertung
- Punkte liegen (ungefähr) auf der
Winkelhalbierenden → Verteilungen stimmen (vermutlich)
überein
- Punkte liegen (ungefähr) auf einer Geraden
→ Verteilungen unterscheiden sich durch Verschiebung und
Skalierung
- Beispiel A, Lebensdauern
- Histogramme der Daten
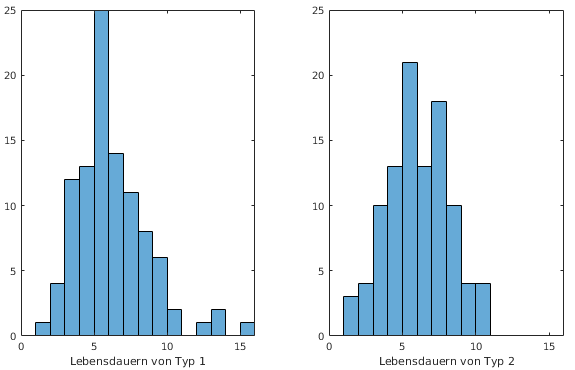
- Vergleich der beiden Typen, jeweils über
i/20-Quantile
- Vergleich des ersten Typs mit Normalverteilung
(dazu Mittelwert und Varianz aus Daten berechnen)
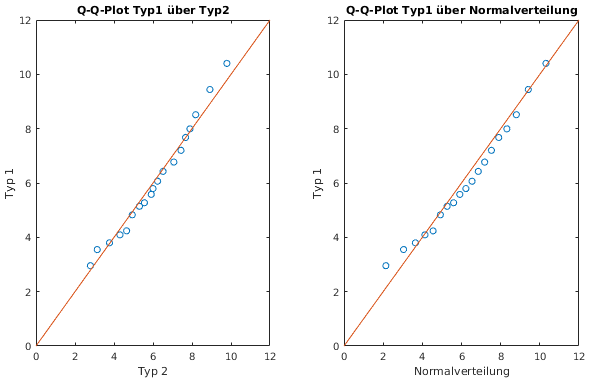
- Interpretation
- Abweichungen von der Winkelhalbierenden klein
→ Verteilungen könnten gleich sein
- typische Links-Krümmung, vor allem im
rechten Plot
- → Typ 1 ist etwas unsymmetrischer, hat
größere Anteile bei hohen Lebensdauern
- → Typ 1 vermutlich nicht normalverteilt
- Aufgaben: