Das Programm POISSON dient zur Bestimmung des elektrostatischen Potentials
bei vorgegebener Ladungsverteilung in zwei Dimensionen. Es basiert auf dem
SOR-Verfahren (''Simultaneous Over-Relaxation''), das z.B. in den ''Numerical
Recipes in C'' von Press, Flannery, Teukolsky und Vetterling beschrieben
ist. Die dort beschriebene SOR-Routine wird - leicht abgewandelt - in
POISSON benutzt.
Das Hauptprogramm steht in main.f, es arbeitet in folgender Weise:
Zunächst wird mit GETSRC die Größe der Ladungs-Matrix und die
Ladungsverteilung selbst bestimmt. Zur Kontrolle und zur Weiterverwendung
bei der späteren bildlichen Darstellung (''Visualisierung'') wird sie mit
WRITEQ in ein File ausgegeben. Da die verwendete SOR-Routine wesentlich
allgemeinere Gleichungen (nämlich beliebige elliptische partielle
Differentialgleichungen) lösen kann, werden zunächst in der Routine
POISSN die allgemeinen Koeffizienten speziell für die Poisson-Gleichung
gesetzt. Mit UINIT wird eine willkührliche Anfangslösung (hier: Potential
U == 0) als Startwert für die Iterationen vorgegeben. Außerdem benötigt
die SOR-Routine noch den Spektralradius RJAC, einen Parameter, der von der
speziellen Form der Gleichung abhängt und der für die Poisson-Gleichung
mit der Funktion SPECR bestimmt wird. Schließlich wird das SOR-Verfahren
durchgeführt und die Lösung mit WRITEU ausgegeben.
- Version 1.1
-
- Änderungen:
-
- Meßergebnisse:
-
| time(-no): |
469 |
. | 6s |
| time(-O0): |
339 |
. | 8s |
| time(-O1): |
242 |
. | 0s |
| time(-O2): |
214 |
. | 9s |
- CXpa:
-
| |
CPU Time |
. | CPU Time |
Times |
. | Routine |
|
|
| |
(less children) |
. | (plus children) |
Called |
. | Name |
|
|
| -O1: |
233 |
. | 170 |
84 |
. | 9% |
233 |
. | 170 |
84 |
. | 9% |
1 |
sor |
| |
0 |
. | 967 |
0 |
. | 4% |
23 |
. | 761 |
8 |
. | 6% |
1 |
writeu |
| |
0 |
. | 798 |
0 |
. | 3% |
17 |
. | 731 |
6 |
. | 5% |
1 |
writeq |
| |
|
. | |
|
. | |
|
. | |
|
. | |
|
|
| -O2: |
198 |
. | 702 |
82 |
. | 7% |
198 |
. | 702 |
82 |
. | 7% |
1 |
sor |
| |
0 |
. | 954 |
0 |
. | 4% |
23 |
. | 338 |
9 |
. | 7% |
1 |
writeu |
| |
0 |
. | 790 |
0 |
. | 3% |
18 |
. | 091 |
7 |
. | 5% |
1 |
writeq |
- Optimierungsbericht für SOR:
-
| Line |
Iter. |
Reordering |
Optimizing Special Special |
Exec. |
| Num. |
Var. |
Transformation |
Transformation |
Mode |
| 34 |
J |
FULL VECTOR Inter |
Reduction |
|
| 35 |
L |
Scalar |
|
|
| |
|
|
|
|
| 48 |
J |
Scalar |
|
|
| 49 |
L |
72% VECTOR |
Reduction |
|
| |
|
|
|
|
| 43 |
IT |
Scalar |
Peel |
|
| 48 |
J |
Scalar |
|
|
| 49 |
L |
72% VECTOR |
Reduction |
|
| |
|
|
|
|
| Line |
Iter. |
Analysis |
|
|
| Num. |
Var. |
|
|
|
| 34 |
J |
Interchanged to innermost |
|
|
| 49 |
L |
Assign to U recurrence on 55 |
|
|
| 43 |
IT |
Loop or inner loop has exit |
|
|
| 49 |
L |
Assign to U recurrence on 55 |
|
|
| |
|
|
|
|
| Line |
Col. |
Test |
Analysis |
|
| Num. |
Num. |
Transformation |
|
|
| 62 |
17 |
TEST REMOVED |
Peeled first iteration of loop on 43 |
|
- Analyse:
-
- skalare Optimierung bis zur Stufe -O1 bringt eine Menge
- schlechter Vektorisierungsgrad
- SOR-Routine Hauptverbraucher, muß besser vektorisiert werden
- entscheidene Schleife in Z.48/49 (Durchgang durch das Gitter)
vektorisiert schlecht wegen komplizierter IF-Bedingung in Z.50
- Bemerkungen:
-
- Die IF-Bedingung in Z.50 bewirkt ein Durchgehen durch das Gitter im
Schachbrett-Muster: Für gerades bzw. ungerades IT werden nur jeweils die
''weißen'' bzw. ''schwarzen'' Felder verändert. Der neue Wert eines
''weißen'' Feldes hängt nur von Werten auf ''schwarzen'' Feldern ab.
Im Bild:
| J |
| 3 |
X |
|
X |
|
|
| |
|
|
|
|
|
| 2 |
|
X |
|
X |
|
| |
|
|
|
|
|
| 1 |
X |
O |
X |
|
|
| |
|
|
|
|
|
| 0 |
|
X |
|
X |
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
0 |
1 |
2 |
3 |
L |
(X: J+L ungerade)
(O: zu veränderndes Feld)
|
Trotz der Meldung im Optimierungsbericht liegt also keine echte
''Recurrence'' in dieser Schleife vor.
- Version 1.2
-
- Änderungen:
-
- Compiler-Direktive ''NO_RECURRENCE'' vor die Schleife in Z.49
- Meßergebnisse:
-
- CXpa:
-
| |
CPU Time |
. | CPU Time |
Times |
. | Routine |
|
|
| |
(less children) |
. | (plus children) |
Called |
. | Name |
|
|
| |
73 |
. | 161 |
63 |
. | 9% |
73 |
. | 161 |
63 |
. | 9% |
1 |
sor |
| |
1 |
. | 026 |
0 |
. | 9% |
23 |
. | 356 |
20 |
. | 4% |
1 |
writeu |
| |
0 |
. | 790 |
0 |
. | 7% |
17 |
. | 877 |
15 |
. | 6% |
1 |
writeq |
- Analyse:
-
- Vektorisierungsgrad deutlich verbessert
- SOR bleibt Hauptverbraucher, aber auch relativ großer CPU-Anteil der
Ausgabe-Routinen
- Bemerkungen:
-
- Wie wir in Abschnitt 4.3.2 gesehen haben, führt eine IF-Bedingung
in einer Schleife auch bei vollständiger Vektorisierung zu
Geschwindigkeitsverlusten. Die komplizierte IF-Bedingung der
''Schachbrett''-Schleifen muß also vereinfacht werden.
- Die Routine WRITEQ war nur zur Kontrolle eingebaut worden, sie kann jetzt
auch entfallen.
- Version 1.3
-
- Änderungen:
-
- IF-Bedingung in Z.51 durch Aufteilen der Schleife in mehrere Teile
weggefallen
- Routine WRITEQ gestrichen
- Meßergebnisse:
-
- CXpa:
-
| |
CPU Time |
. | CPU Time |
Times |
. | Routine |
|
|
| |
(less children) |
. | (plus children) |
Called |
. | Name |
|
|
| |
47 |
. | 953 |
66 |
. | 9% |
47 |
. | 953 |
66 |
. | 9% |
1 |
sor |
| |
1 |
. | 132 |
1 |
. | 6% |
23 |
. | 741 |
33 |
. | 1% |
1 |
writeu |
- Analyse:
-
- SOR deutlich schneller
- relativer Anteil von WRITEU sehr gestiegen
- Bemerkungen:
-
- Durch die geänderte Reihenfolge der Berechnungen hat sich in der
Ergebnisdatei ein Wert minimal geändert.
- Version 1.4
-
- Änderungen:
-
- In WRITEU implizite DO-Liste statt expliziter Schleife
- Meßergebnisse:
-
- CXpa:
-
| |
CPU Time |
. | CPU Time |
Times |
. | Routine |
|
|
| |
(less children) |
. | (plus children) |
Called |
. | Name |
|
|
| |
48 |
. | 284 |
81 |
. | 3% |
48 |
. | 284 |
81 |
. | 3% |
1 |
sor |
| |
0 |
. | 460 |
0 |
. | 8% |
11 |
. | 059 |
18 |
. | 6% |
1 |
writeu |
- Analyse:
-
- Array-Ausgabe durch implizite DO-Liste schneller
- Bemerkungen:
-
- Die Schachbrett-Struktur in SOR legt zur Erzeugung längerer Vektoren
ein Durchlaufen des Arrays längs der Diagonal-Richtungen nahe. Dazu
verhilft folgender Trick: Die Differentialgleichung wird nicht direkt,
sondern nach einer Drehung der x-y-Ebene um 45
 diskretisiert.
Dies führt (neben einem Faktor
diskretisiert.
Dies führt (neben einem Faktor 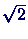 ) dazu, daß beim Updaten
statt der direkten jetzt die diagonalen Nachbarn benötigt werden.
Vorteil: Eine ganze Spalte kann upgedatet werden, ohne daß innerhalb der
Spalte Rückgriffe auftreten. Die Numerik wird dabei eher besser. Der
so veränderte Algorithmus heißt ''XSOR''.
) dazu, daß beim Updaten
statt der direkten jetzt die diagonalen Nachbarn benötigt werden.
Vorteil: Eine ganze Spalte kann upgedatet werden, ohne daß innerhalb der
Spalte Rückgriffe auftreten. Die Numerik wird dabei eher besser. Der
so veränderte Algorithmus heißt ''XSOR''.
- Version 1.5
-
- Änderungen:
-
- Algorithmus von SOR in XSOR geändert
- Meßergebnisse:
-
- CXpa:
-
| |
CPU Time |
. | CPU Time |
Times |
. | Routine |
|
|
| |
(less children) |
. | (plus children) |
Called |
. | Name |
|
|
| |
28 |
. | 210 |
70 |
. | 8% |
28 |
. | 210 |
70 |
. | 8% |
1 |
sor |
| |
0 |
. | 377 |
0 |
. | 9% |
11 |
. | 612 |
29 |
. | 1% |
1 |
writeu |
- Analyse:
-
- XSOR ist deutlich schneller als SOR
- Bemerkungen:
-
- Wir erhalten im Rahmen unserer Genauigkeit etwas abweichende
Ergebnisse; man müßte also beide bei höherer Genauigkeit vergleichen.
In unserem Fall überzeugen wir uns nur qualitativ (durch Visualisieren
mit Unigraph) davon, daß die Ergebnisse im wesentlichen übereinstimmen.
- Um die Speicherzugriffe zu beschleunigen, betrachten wir verschiedene
Werte für die physikalische Arraygröße NMAX:
| NMAX |
Zeit |
Bemerkung |
|
| 300 |
38 |
. | 4 |
Ausgangswert |
| 301 |
37 |
. | 4 |
ungerade Dimension ist meist besser |
| 320 |
214 |
. | 5 |
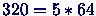 (= Interleave): max. Bankkonflikte (= Interleave): max. Bankkonflikte |
| 321 |
28 |
. | 0 |
1 größer als
 : Optimaler Wert! : Optimaler Wert! |
- Version 1.6
-
- Änderungen:
-
- phys. Arraygröße in NMAX=321 geändert
- Meßergebnisse:
-
- Analyse:
-
- Verringerung der Bankkonflikte bringt deutliche Beschleunigung
- Bemerkungen:
-
- Die allgemeine SOR-Routine kann durch direkte Anpassung an die
Poisson-Gleichung noch stark vereinfacht werden.
- Version 1.7
-
- Änderungen:
-
- Koeffizienten-Arrays A - E in SOR durch Konstanten ersetzt
- POISSN gestrichen
- Meßergebnisse:
-
- CXpa:
-
| |
CPU Time |
. | CPU Time |
Times |
. | Routine |
|
|
| |
(less children) |
. | (plus children) |
Called |
. | Name |
|
|
| |
13 |
. | 833 |
55 |
. | 4% |
13 |
. | 833 |
55 |
. | 4% |
1 |
sor |
| |
0 |
. | 379 |
1 |
. | 5% |
11 |
. | 132 |
44 |
. | 6% |
1 |
writeu |
- Analyse:
-
- Zeit für SOR mehr als halbiert
- Ausgabe mit WRITEU hat nun großen relativen Anteil
- Bemerkungen:
-
- Um den I/O-Anteil zu drücken, soll die Array-Ausgabe unformatiert
erfolgen. Da die Daten hinterher mit Unigraph ausgewertet werden sollen,
das nur REAL-Daten binär einlesen kann, wird mit der REAL-Funktion
explizit nach REAL gewandelt.
- Version 1.8
-
- Änderungen:
-
- Ausgabe in WRITEU unformatiert
- Meßergebnisse:
-
- CXpa:
-
| |
CPU Time |
. | CPU Time |
Times |
. | Routine |
|
|
| |
(less children) |
. | (plus children) |
Called |
. | Name |
|
|
| |
13 |
. | 057 |
92 |
. | 4% |
13 |
. | 057 |
92 |
. | 4% |
1 |
sor |
| |
0 |
. | 331 |
2 |
. | 3% |
1 |
. | 065 |
7 |
. | 5% |
1 |
writeu |
- Analyse:
-
- Anteil von WRITEU hat drastisch abgenommen
- Bemerkungen:
-
- Bei genauerer Betrachtung der Zeiten wird deutlich, daß etwas
nicht stimmen kann: Der Anteil von writeu in Version 1.7 betrug fast
die Hälfte der CPU-Zeit von 16.7s, nämlich etwa 7.4s. In Version
1.8 soll der Anteil von WRITEU auf nahezu vernachlässigbare 7.5%
gesunken sein. Das bedeutet aber, daß die Gesamtzeit auch um etwa 7s
zurückgehen müßte. Tatsächlich ist sie aber nur um 2.9s
gesunken! Wie sich nach längerem Testen, insbesondere mit expliziten
Aufrufen von CPUTIME in main.f, herausstellte, liegt hier ein Bug des
CXpa (Version 1.3) vor: Die Zeiten für FORTRAN-Writes sind immer
wesentlich zu hoch!
- Version 1.9
-
- Änderungen:
-
- CPUTIME-Aufrufe eingefügt, um die Zeiten für WRITEU und SOR explizit
zu messen
- Meßergebnisse:
-
| Zeit |
: | 13 |
. | 8s |
| SOR |
: | 13 |
. | 4s |
| WRITEU |
: | 0 |
. | 3s |
zum Vergleich analoge Messung mit Version 1.7:
| Zeit |
: | 16 |
. | 7s |
| SOR |
: | 13 |
. | 6s |
| WRITEU |
: | 3 |
. | 1s |
- Analyse:
-
- Wie man sieht, hat der Anteil von writeu tatsächlich drastisch
abgenommen, wenn er auch nie so groß war, wie uns die CXpa-Ergebnisse
glauben ließen.
- Bemerkungen:
-
- Neben der höheren Ausgabegeschwindigkeit besteht ein weiterer
Vorteil des unformatierten Schreibens darin, daß auch das Einlesen der
Daten in Unigraph jetzt wesentlich schneller geht. Übrigens hat der
vermeintliche Nachteil (Wandlung nach
 für Unigraph) sich
zeitlich nicht ausgewirkt: Ein direktes Herausschreiben der
für Unigraph) sich
zeitlich nicht ausgewirkt: Ein direktes Herausschreiben der
 -Daten ist im Gegenteil sogar langsamer - wegen der doppelt
so großen Datenmenge!
-Daten ist im Gegenteil sogar langsamer - wegen der doppelt
so großen Datenmenge!
- Beim Arbeiten mit unformatierten Daten ist noch darauf zu achten,
daß die Formate i.a. maschinenspezifisch sind, so daß eine Auswertung
ohne Wandlung nur auf Maschienen möglich ist, die das gleiche Datenformat
verwenden. Allerdings benutzen fast alle gängigen Workstations und die
Convex für Fließkommazahlen das von der IEEE genormte Format, so daß
normalerweise keine Probleme auftreten sollten.
- Parallelisierung
-
- Änderungen:
-
- Version 1.8, sor.f mit -O3 übersetzt
- Meßergebnisse:
-
| time(-O3): |
8 |
. | 9s |
real |
| 19 |
. | 8s |
user |
| 0 |
. | 2s |
system |
- CXpa:
-
| Parallel Region Performance Analysis |
|
|
. | |
| For sor.f:sor |
|
|
. | |
| |
|
|
. | |
| Line |
Num Exec |
Cpu Time |
Wall Clock Time |
. | Process Virtual |
. | CPU/PVT |
. | |
| Num |
|
Time |
|
. | |
|
. | |
| 34 |
1 |
0 |
. | 002797 |
0 |
. | 001849 |
0 |
. | 001756 |
1 |
. | 59282 |
| 48 |
296 |
0 |
. | 023810 |
0 |
. | 039057 |
0 |
. | 021411 |
1 |
. | 11205 |
| 48 |
260184 |
20 |
. | 956636 |
84 |
. | 758220 |
19 |
. | 041363 |
1 |
. | 10058 |
- Analyse:
-
- Parallelisierungsgewinn nach time-Ergebnis:
 2.2
2.2
gemessen bei einem weiteren Job im System
- Parallelisierungsgewinn nach CXpa-Messung:
 1.1
1.1
- Bemerkungen:
-
- Schleife in Z.48 taucht zweimal auf, weil wegen des Tests in Z.59
der Wert IT=1 der Hauptschleife (Z.42) herausgezogen wurde
- Die Meßwerte des CXpa sind nicht konsistent mit der einfachen
time-Messung!
- Eigene Messungen mit der Routine PARUSE (s. 4.4.3) ergeben einen
Wert von 2.9 für die Parallelität (concurrency'') der SOR-Routine,
in Übereinstimmung mit dem time-Wert.
- Zusammenfassung der Optimierungen:
-
| Version |
time(-O2)/s |
Änderungen |
|
| 1.1 |
214 |
. | 9 |
Ausgangsversion |
| 1.2 |
86 |
. | 4 |
Compiler-Direktive in sor.f eingefügt |
| 1.3 |
54 |
. | 7 |
Schleifen in sor vereinfacht, writeq gestrichen |
| 1.4 |
51 |
. | 3 |
Ausgabe durch implizite DO-Liste in writeu.f |
| 1.5 |
38 |
. | 4 |
sor in xsor geändert |
| 1.6 |
28 |
. | 0 |
Arraygröße von 300 auf 321 gesetzt |
| 1.7 |
16 |
. | 7 |
Koeffizientenmatrizen in sor durch Konstanten ersetzt |
| 1.8 |
13 |
. | 8 |
Ausgabe in writeu.f binär |
Zum Vergleich: Zeiten der verschiedenen Versionen auf einer HP9000/720:
| Version |
Optionen |
Zeit |
|
| 1.1 |
-A |
|
1399 |
. | 3s |
| |
-A |
+O3 |
666 |
. | 6s |
| 1.2 |
|
|
| 1.3 |
-A |
+O3 |
650 |
. | 4s |
| 1.4 |
|
|
| 1.5 |
-A |
+O3 |
469 |
. | 6s |
| 1.6 |
-A |
+O3 |
464 |
. | 0s |
| 1.7 |
-A |
+O3 |
167 |
. | 5s |
| 1.8 |
-A |
+O3 |
165 |
. | 5s |




Peter Junglas 18.10.1993