Hashing und assoziative Arrays
-
Grundprinzip:
- Speicherung grundsätzlich in einem Feld fester
Größe N
- Hashfunktion h berechnet zu einem Schlüssel e den
Indexwert h(e) im Array
-
Anforderungen an h
- verschiedene Elemente haben möglichst
verschiedenen Index
- möglichst gleichmäßige Verteilung der Werte
auf den Indexbereich
- besondere Maßnahmen treffen bei verschiedenenen
Schlüsseln mit gleichem Index (Kollision)
-
Hashfunktionen:
-
für Integer-Schlüssel am einfachsten
- h(i) = i % N
- N am besten Primzahl!
- alternativ mehr streuende Funktionen, etwa
Polynome
-
bei double als Schlüssel z.B.
- Exponent und Mantisse addieren und dann
Hashfunktion für Integer
- Zerlegung des Bitmusters in mehrere Integer,
addieren, hashen
-
bei Strings
- ASCII/Unicode-Werte der einzelnen Zeichen als
Grundlage
- daraus einen Integerwert ableiten (addieren,
Polynom) und hashen
-
Hash-Methode in java.lang.Object
- int hashCode()
- liefert int-Hashwert
für beliebiges Object
- mit modulo an N anpassen
- basiert in der Regel auf interner
Speicheradresse
- kann überschrieben werden durch an Daten
angepasste Funktion (z.B. bei String)
-
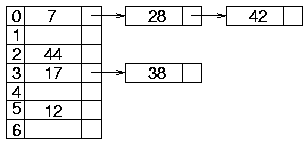
Kollisionsbehandlung:
- Problem: Feld für neuen Schlüsselwert ist schon
belegt (mit anderem Schlüssel)
-
Lösungsmöglichkeit: an Index-Position verkettete Liste der
Elemente ansetzen
-
Alternative:
- neuen Platz suchen (Sondieren)
- muss ggf. mehrmals probiert werden
-
Sondierungsfunktion
- liefert neue Schlüssel ik, falls
alte (i0, i1, ..) besetzt
- direkt daneben: ik = i0
+ k
- linear: ik = i0 +
k*step
- quadratisch: ik = i0 +
k2
- jeweils modulo N zu nehmen
-
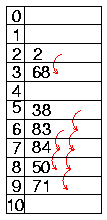
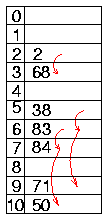
Beispiel:
- Eingabewerte 84, 2, 68, 38, 83, 50, 71
- Integer-Schlüssel mit einfacher
Modulo-Hashfunktion
-
Sondierungsfunktion in Einer-Schritten
- Bildung von dichtbesetzten Haufen
- 7 Kollisionen
-
quadratische Sondierungsfunktion
- bessere Verteilung der Werte
- 5 Kollisionen
-
Aufwand beim Hashing:
- stark abhängig vom Füllgrad
- abhängig von Güte der hash- und
Sondierungsfunktionen
- typische Anzahl S von Suchschritten bei linearem Sondieren
[Wirth]
|
Füllgrad
|
S
|
| 0.1 |
1.06 |
| 0.25 |
1.17 |
| 0.5 |
1.50 |
| 0.75 |
2.50 |
| 0.9 |
5.50 |
| 0.95 |
10.50 |
-
Vorteile gegenüber anderen Suchverfahren
- bei nicht zu hohem Füllgrad Einfügen und
Aufsuchen in konstanter Zeit!
-
Nachteile
- Probleme bei hohem Füllgrad bzw. unbekannter
Anzahl auftretender Werte
- statisch vorgegebene Array-Größe
- u.U. Schwierigkeiten der Hash-Funktion bei
speziellen Daten
-
Assoziatives Array (Map):
- Zuordnung von Schlüsseln und Werten, jeweils von
beliebigem Typ
- vorstellbar als "Array mit nicht-ganzzahligem
Index"
-
z.B. Tabelle von Benutzernamen und Passwörtern (in Perl-Syntax)
- tabelle{"peter"} =
"programmieren";
tabelle{"thomas"} = "schweißen";
tabelle{"gaby"} = "beweisen";
print tabelle{"thomas"}; // liefert "schweißen"
- häufig als Hashtabelle implementiert
-
in Java java.util.HashMap mit (u.a.)
folgenden Methoden
- Object put(Object key,
Object value)
legt value unter Schlüssel key ab
- Object get(Object
key)
liefert Wert zum Schlüssel key
- String toString()
erzeugt Ausgabe-String mit allen Werten in der Form
{key1=wert1, key2=wert2, ...}
-
Aufgaben: