Die Änderung, die die Nutzer des HP-Clusters am meisten erfreuen wird, betrifft interne Verbesserungen am Routing-Algorithmus, die die Übertragung von großen Blöcken stark beschleunigen. So habe ich mit PVM3.2 bei der Benutzung von direktem Routing maximal 4.4 MB/s gemessen, bei PVM3.3 dagegen 9.4 MB/s. Eine weitere Erhöhung der Geschwindigkeit kann man durch Verringerung der ``Packzeit'' der Message-Buffer erreichen. In einem homogenen Cluster kann man etwa mit PvmDataRaw das Umrechnen auf eine rechner-unabhängige Darstellung einsparen. Falls man nur zusammenhängende Daten verschicken will (Stride = 1), kann man nun auch die Option PvmDataInPlace benutzen, um auch das Kopieren der Daten in den Buffer zu verhindern. Für 64k-Blöcke wirken sich die Optionen folgendermaßen aus:
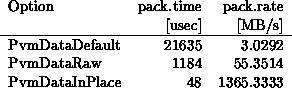
Allerdings muß man beim Versenden nicht gebufferter Daten selber dafür sorgen, daß die Daten nicht geändert werden, bevor sie beim Empfänger angekommen sind.
Bei der Option PvmDataInPlace wird i.w. nur ein Pointer auf die Daten in den Buffer gepackt. Auch dies kann man sich noch sparen und ganz ohne Buffer (d.h. ohne vorheriges pvm_initsendund pvm_pkstar) Daten verschicken bzw. empfangen mit den neuen Routinen pvm_psendund pvm_precv:
int pvm_psend(int tid, int msgtag, char *buf, int len, int datatype)
int pvm_precv(int tid, int msgtag, char *buf, int len, int datatype)
Die ersten beiden Argumente beschreiben wie üblich Sender/Empfänger und Tag
der Nachricht, die nächsten drei den Inhalt: Ort, Länge und Datentyp. Der
Typ kann nur ein einfacher Typ in C oder Fortran sein, beschrieben durch
eine in PVM vordefinierte Konstante. Angabe eines Strides ist nicht möglich.
Beide Routinen können auch als Partner eines normalen Receives/Sends
auftreten, sie müssen nicht gepaart werden.
Ebenfalls neu ist die Routine pvm_trecv. Mit ihr kann man ein blockierendes Receive mit einem Timeout verbinden: Ist die Nachricht nach Ablauf einer vorgegeben Zeit nicht angekommen, kommt die Routine mit einem entsprechenden Code zurück. Damit kann man sein Programm gegen Rechnerausfälle (und Programmierfehler!) robuster machen.
Im Bereich ``kollektive Kommunikation'' hat sich Wichtiges getan: Neben dem Broadcast und der Barrier gibt es jetzt drei weitere Routinen: pvm_reduceerlaubt das Bilden von globalen Summen, Produkten, Minima oder Maxima (oder auch selbstdefinierter Funktionen) über die Daten aller Gruppen-Mitglieder. Das Ergebnis steht im Buffer eines auserwählten Mitglieds. Mit pvm_gatherkann eine Task Daten von allen Tasks einer Gruppe in einem Array sammeln, mit pvm_scatterumgekehrt Daten an alle verteilen. Wie bei allen Gruppen-Operationen muß man aber sehr vorsichtig mit der Synchronisation sein und häufig mit pvm_barriersynchronisieren, sonst geschieht z.B. folgendes:
Alle Tasks werden Mitglied einer Gruppe, machen ein reduce, dann verlassen sie die Gruppe. Das Ergebnis ist abhängig von der Geschwindigkeit der Rechner, denn: der erste ist eventuell schon wieder aus der Gruppe heraus, bevor der letzte sein Reduce angefangen hat. Also Vorsicht!
Neu ist auch die Routine pvm_catchout, die den Output aller Tasks auf ein File (in PVM3.3.0 nur nach stdout) umlenkt. Sie sollte vom Master vor dem ersten pvm_spawnaufgerufen werden.
Für sehr fortgeschrittene PVM-Programmierer, die ihre eigenen Profiler oder Debugger für PVM schreiben wollen, sind die Routinen pvm_reg_hoster, pvm_reg_taskerund pvm_reg_rmhinzugekommen. Näheres dazu findet man im Online-Manual.
Schließlich sind noch zwei kleine Änderungen zu erwähnen: Die Strukturen hostinfo und taskinfo wurden umbenannt in pvmhostinfo und pvmtaskinfo; und die Routinen pvm_serror, pvm_adviseund pvm_setdebugsind weggefallen, da sie seit PVM3.2 durch pvm_setoptund pvm_getoptersetzt wurden.