Der von der DFG im Rahmen des Projektes ``Paralleles Rechnen in technischen Anwendungen'' zur Verfügung gestellte GC 64 (Betreuung durch das IuK-Labor, Leitung: Dr. Hiller) ist ein Parallelrechner mit verteiltem Speicher, der aus 64 Knoten mit je 2 Power PC Prozessoren und je einem 8 MB Speicherchip besteht. Die Kommunikation der Knoten miteinander wird über die Links eines auf dem Knoten liegenden Transputers geführt. Das Laufzeitsystem des GC 64, Parix, stellt über Bibliotheksfunktionen die für die Kommunikation der Prozessoren untereinander notwendigen Sende- und Empfangsroutinen zur Verfügung und beinhaltet damit eine dem MPI-Standard vergleichbare Funktionalität.
Wesentlicher Unterschied zwischen beiden Parallelrechnern ist die Form der Speicherverwaltung.
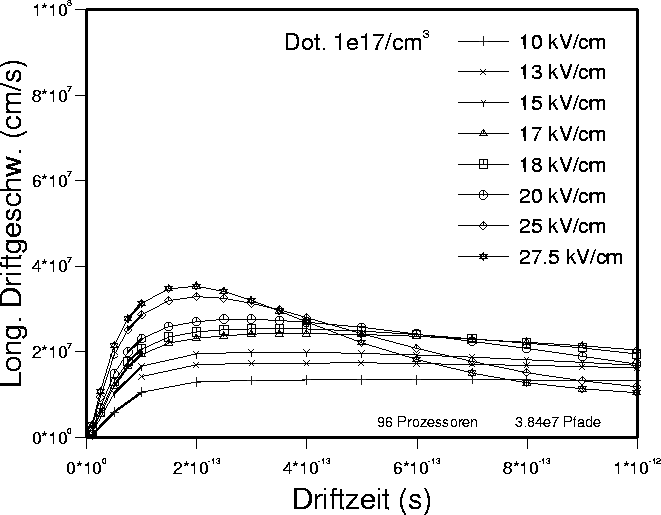
Abbildung 9: Klassische Rechnung: Vergleich der longitudinalen
Driftgeschwindigkeiten für verschiedene Feldstärken bei
der Ionisierte-Störstellendichte von 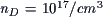 bei Raumtemperatur.
bei Raumtemperatur.
Während Hydra den shared memory-Typ vertritt, ist der GC 64 ein System mit verteiltem Speicher.
Für die parallelisierte Berechnung eines numerischen Problems ist gerade die Plazierung von Datenmengen geeigneter Größe auf den dezentralen Speichereinheiten der Knoten von großer Bedeutung. Die Kommunikationsleistung der Prozessoren dient ja dazu, die verteilten Daten bedarfsgemäß anderen Prozessoren zur Verfügung zu stellen. Zu kleine Datenmengen erfordern zu viel Verschieben der Daten, zu große Datenmengen führen, sofern die Bearbeitungszeiten der verschiedenen Datenmengen voneinander abweichen, zu verschwendeten Wartezeiten einiger Prozessoren, i.e. einem Performanceverlust.
Diese Überlegungen sind auf Hydra nicht erforderlich. Alle Daten können topologisch global (d.h. auf jedem Prozessor) bekannt gegeben werden. Man hat lediglich zu beachten, daß es nicht zu einem Überlappen von Bearbeitungsprozessen auf dem gleichen Datenblock kommt.
Bei der Portierung der GC -Version waren nur die SendLink()- und ReceiveLink()-Funktionen aus Parix-C durch entsprechende MPI-Funktionen MPI_Bcast(), MPI_Recv(), bzw. MPI_Send() zu ersetzen. Dank der maßgeblichen Unterstützung durch Dr. Junglas konnte das Programm bereits nach einem halben Tag auf Hydra laufen.
Auf Hydra konnte der Diskretisierungsgrad des Impulsraums deutlich vergrößert werden. Dabei konnte empirisch geprüft werden, daß die Ergebnisse vom Diskretisierungsgrad nicht signifikant abhängen.
In der bisherigen Programmierweise konnte die hohe numerische Leistungsfähigkeit auf Hydra nicht ausgeschöpft werden, so daß ein Leistungsvergleich mit dem GC bisher ergibt, daß das gleiche Programm auf 4 Prozessoren des GC's etwa doppelt so schnell läuft, wie auf 4 Prozessoren von Hydra. Dieses Verhältnis läßt sich mit Unterstützung des Rechenzentrums sicherlich noch zugunsten von Hydra verbessern.
Catrin Schulz-Mirbach, Tel.: 2218
AB Elektrotechnik III