Bei einer Untersuchung mit dem Ziel, die Geschwindigkeit von Message-Passing- und Shared-Memory-Programmiermodell auf dem SPP-System zu vergleichen, trat die Frage auf, wie schnell eigentlich ein Integer-Array in ein anderes kopiert werden kann. Die Beantwortung dieser scheinbar einfachen Frage führte zu einigen interessanten Phänomenen, die im folgenden vorgestellt werden sollen.
Als Rahmen diente ein kleines Testprogramm, das Buffer wachsender Größe mit verschiedenen Methoden kopierte und die Zeit dazu möglichst genau maß. Da jeder Versuch oft wiederholt wurde, spielte sich das Kopieren - bei nicht zu großem Buffer - im Cache ab. Zum Vergleich wurden jedes Mal die Caches geflushed (mit der SPP-spezifischen Routine cache_flush_region). Typische Ergebnisse sahen etwa so aus:
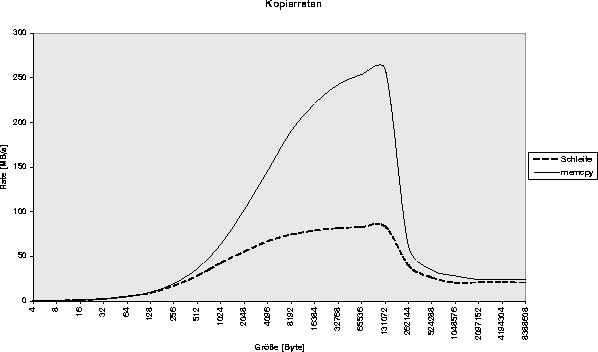
Für alle untersuchten Methoden sind die Ergebnisse ähnlich: Bei kleinen Buffern beträgt die Zeit immer etwa 12 Mikrosekunden, die Rate steigt dann bis zu einer Buffergröße von 128 - 256 kB auf einen Maximalwert an und sinkt danach schnell auf den Wert von 20 - 25 MB/s, der der Durchsatzrate ohne Cache-Beteiligung entspricht. Soweit ist das alles nicht sehr erstaunlich und entsprach auch meinen Erwartungen. Zunächst überraschend aber waren die großen Unterschiede der maximalen Durchsatzrate bei verschiedenen Verfahren:
Die einfache Schleife
for (i=0; i<noInts; i++)
{
dest[i] = source[i];
}
erreichte 80 MB/s, die C-Standardroutine
memcpy(dest, source, noInts*sizeof(int));dagegen fast 260 MB/s!
Zum Vergleich untersuchte ich verschiedene Möglichkeiten in Fortran. Die
folgende Tabelle faßt alle Ergebnisse zusammen:
| Schleife | C | 80 MB/s |
| Schleife | Fortran | 104 MB/s |
| A(1:MAX) = B(1:MAX) | Fortran | 104 MB/s |
| A = B | Fortran | 254 MB/s |
| icopy (BLAS-Routine) | Fortran | 254 MB/s |
| memcpy (Standard-Bibliothek) | C | 258 MB/s |
Wo kommen diese eklatanten Unterschiede her? In Ermangelung des Source-Codes der Bibliotheksroutinen mußte der Assembler-Code herhalten. Außer bei ganz alten Hasen (zu denen ich mich nicht zähle :-) ruft das Wort ``Assembler'' wahlweise Ekel oder Angstschweiß hervor. Es war aber alles gar nicht so schlimm: Mit dem Debugger war die kleine Loop von etwa 20 Zeilen Assembler, die die eigentliche Arbeit macht, schnell gefunden. Und auch ohne jede Zeile im einzelnen verstehen zu wollen, war das Muster leicht gedeutet:
1. memcpy kopiert Double-Zahlen, nicht Integers.
Darauf hätte ich natürlich auch gleich kommen können. Ich schrieb die
kleine Schleife in C so um, daß sie die Integer-Arrays über Double-Pointer
anfaßt (brrr!) und ab geht's:
| Schleife (ints als doubles) | C | 160 MB/s |
Doppelt so schnell wie vorher - wer hät's gedacht.
2. memcpy verteilt Loads und Stores anders:
| memcpy | eigene Schleife |
| LOAD | LOAD |
| LOAD | STORE |
| LOAD | LOAD |
| LOAD | STORE |
| STORE | LOAD |
| STORE | STORE |
| STORE | LOAD |
| STORE | STORE |
Durch das Anstoßen von vier Loads direkt nacheinander wird anscheinend die
CPU besser ausgenutzt, Wartezeiten werden
minimiert. [1]
Soviel Intelligenz hätte ich aber - mit Verlaub - dem Compiler
bei einer einfachen Kopier-Schleife auch zugetraut! Dies zeigt wieder
einmal, daß der Convex-Compiler, bei allen Vorteilen im Optimierungsbereich
auf Source-Ebene, im Code-Generator noch sehr zu wünschen übrig läßt! Zum
Vergleich hier die Werte für den HP-C-Compiler bei +O3 (auf der SPP):
| Schleife | C | 97 MB/s |
| Schleife (double *) | C | 252 MB/s |
| memcpy (Standard-Bibliothek) | C | 111 MB/s |
Im Instruktions-Scheduling ist der HP-Compiler eindeutig überlegen, er erzeugt aus der handoptimierten Schleife tatsächlich idealen Code. Aber was macht bloß das memcpy von HP? Wieder ein schon von anderen Untersuchungen her bekanntes Resultat: Die Bibliotheksroutinen von HP können denen von Convex nicht das Wasser reichen. Dies war mir schon im Zusammenhang mit der Veclib für HP-UX aufgefallen. Zum Glück werden die Teams von HP und Convex ja gerade zusammengewürfelt. Hoffen wir, daß sich jeweils die besseren Teile zusammenfinden.
Was lernen wir nun daraus? Zunächst einmal sollte man immer eine Bibliotheksroutine verwenden, wenn eine da ist - selbst bei scheinbar so einfachen Operationen wie einem Kopieren oder etwa einer Matrix-Multiplikation. Wenn man insbesondere die BLAS-Routinen der Veclib verwendet, erreicht man hohe Performance bei weitgehender Portabilität. Außerdem ist es sinnvoll - und der Lesbarkeit des Programmes zuträglich -, in Fortran mit den Array-Operationen von Fortran 90 zu arbeiten.
[1] Ganz verstanden habe ich das nicht - aber die Convex-Leute, die ich gefragt habe, auch nicht :-)