Die FDTD Methode
Die FDTD Methode (``Finite Difference Time Domain'') wird benutzt, um elektromagnetische Felder in einer hochfrequenten Struktur im Zeitbereich zu berechnen. Diese Struktur kann z.B. eine passive Schaltung sein, die aus einem Hohlleiter besteht, mit möglichen Diskontinuitäten und mit der Einfügung von metallischen und dielektrischen Materialien. Die Schaltung wird an einem Eingangstor angeregt und das Signal kommt an einem (oder mehr als einem) Ausgangstor heraus.
Die Methode besteht darin, die partiellen Ableitungen der Maxwellschen Gleichungen durch finite Differenzen zu ersetzen. Die ganze Struktur wird dafür in Zellen geteilt, in denen jede Feldkomponente eine bestimmte Stellung einnimmt. Das führt zu sechs Aktualisierungsgleichungen, eine für jede Komponente des elektrischen bzw. magnetischen Feldes. Mit diesen Gleichungen werden die Feldkomponenten von den Werten einen Zeitschritt davor berechnet. Die Struktur wird mit einer Gauß-förmigen Anregung angestoßen.
Das Programm FDTD3D
Das Programm rechnet die Streuparameter von einer hochfrequenten passiven Schaltung mit Hilfe der FDTD Methode. Die Geometrie der Struktur wird angegeben.
In einer ersten Etappe teilt das Programm die Struktur den elektrischen Parametern nach in Blöcke und jeden Block dann gleichmäßig in Zellen. Die Koeffizienten für die Aktualisierungsgleichungen werden für jeden Block berechnet.
Der nächste Schritt ist die Berechnung der Eigenschaften des Eingangstores. Diese Berechnung wird in einem zweidimensionalen Netz durchgeführt und ergibt die Impedanz und Ausbreitungskonstante der Eingangsleitung, die für die weitere Berechnung wichtig sind, sowie die Feldverteilung am Eingang, die für die Anregung der Struktur benutzt wird.
Dann wird erst die Berechnung in der gesamten Struktur dreidimensional durchgeführt. Ein Schritt der Berechnung besteht aus vier Etappen: das magnetische Feld wird aktualisiert, seine Randbedingungen werden in jedem Block erfüllt, dann wird das elektrische Feld aktualisiert und anschließend seine Randbedingungen erfüllt. Für die Randbedingungen in einem Block gibt es folgende Möglichkeiten: elektrische Wand, magnetische Wand, Absorber oder Nachbar von einem anderen Block. Dieser Schritt wird so oft wiederholt, bis das Feld in der Struktur genügend gering ist.
Diese letzte Etappe hat den wesentlichen Anteil am CPU-Zeitverbrauch, weil der Schritt ziemlich oft wiederholt wird (in einigen Fällen über 100000 mal). Der Schritt selber ist größer als der Schritt in der zweidimensionalen Berechnung. Dabei ist aber zu erwarten, daß der Schritt sich gut parallelisieren läßt, weil die Berechnung in einem Block von der in den anderen Blöcken unabhängig ist.
Parallelisierung von FDTD3D, 1.Versuch
Der für die Parallelisierung relevante Teil von FDTD3D hat vereinfacht folgende Form:
do n = 1, maxn
call schrittb
call randb
call schritte
call rande
enddo
Die vier aufgerufenen Routinen sind in ihrer Struktur sehr ähnlich; allen gemeinsam ist eine äußere Schleife über Blöcke:
subroutine schrittb
integer q, qmax
do q = 1, qmax
tue jede Menge mit vielen Arrays
enddo
Da im Innern der q-Schleifen keine Abhängigkeiten von Werten mit anderem q-Wert auftreten, können sie direkt parallelisiert werden; dies macht sogar der Compiler bei -O3 automatisch. Der Erfolg dieser Maßnahme ist allerdings, daß die Rechenzeit (Real-Zeit!) stark mit der Zahl der CPUs anwächst! Die Erklärung für dieses Verhalten ist bald gefunden: Zwar verbrauchen die vier untersuchten Routinen den weitaus größten Anteil der gesamten CPU-Zeit, aber ein einzelnener Aufruf ist jeweils sehr kurz, er liegt im Bereich weniger Millisekunden. Bei jedem der vielen (maxn 10000) Aufrufe werden zunächst parallele Threads erzeugt, Indizes für die q-Schleife aufgeteilt, die entsprechenden Schleifenanteile berechnet und schließlich alle Threads bis auf einen wieder beendet. Hier ist der Overhead wesentlich größer als der Gewinn!
Parallelisierung von FDTD3D, 2.Versuch
Um den Overhead zu verringern, sollten die Threads nur einmal zu einem frühen Zeitpunkt erzeugt werden und sich dann jeweils um einen bestimmten Bereich von q-Werten kümmern. In vereinfachter Form sieht der Code dann etwa so aus:
! erzeuge n_cpu parallele Threads
call spawn_threads(n_cpu)
! berechne die Zerlegung der q-Werte auf die Threads
call get_thread_limits(tqmin, tqmax, tdq)
do n = 1, maxn
call schrittb(tqmin, tqmax, tdq)
call randb(tqmin, tqmax, tdq)
call schritte(tqmin, tqmax, tdq)
call rande(tqmin, tqmax, tdq)
enddo
! beende die parallelen Threads - bis auf einen natürlich
call join_threads(n_cpu)
und die Routinen werden entsprechend ergänzt:
subroutine schrittb(tqmin, tqmax, tdq)
integer q, tqmin, tqmax, tdq
do q = tqmin, tqmax, tdq
tue jede Menge mit vielen Arrays
enddo
Ein Problem, das jetzt auftritt, ist die Synchronisation der Threads: Beispielsweise darf die Routine randb erst aufgerufen werden, nachdem neue Werte für alle q von 1 bis qmax in schrittb berechnet worden sind. Daher muß man zwischen die Calls jeweils Warte-Punkte einfügen, an der ein Thread so lange anhält, bis alle anderen auch dort angekommen sind. Die n-Schleife sieht dann so aus:
do n = 1, maxn
call wait_barrier
call schrittb(tqmin, tqmax, tdq)
call wait_barrier
call randb(tqmin, tqmax, tdq)
call wait_barrier
call schritte(tqmin, tqmax, tdq)
call wait_barrier
call rande(tqmin, tqmax, tdq)
enddo
Analyse der Rechenzeiten
Als Testfall diente ein einfaches Modell mit qmax=20 Blöcken und einer Laufzeit von etwa 4 Minuten. Der CPU-Anteil der untersuchten Routinen liegt hier bei 81%.
Zunächst einmal wollen wir abschätzen, wieviel mit unserem Vorgehen maximal an Beschleunigung (``Speedup'') erreicht werden kann: Da ein Anteil von 19% nicht parallelisiert wurde, kann man mehr als einen Faktor 5 auch auf beliebig vielen CPUs nicht erreichen (``Amdahl's Law''). Genauer erhält man bei optimaler Parallelisierung von 81% z.B. für 5 CPUs einen maximalen Speedup von 2.8.
Im ersten Versuch wurde auf 5 CPUs nur eine Beschleunigung von 1.3 erzielt. Als Ursache stellte sich ein schlechtes Load-Balancing heraus: Die Rechenzeiten sind nicht für alle Blöcke (d.h. Werte von q) gleich, so daß bei ungünstiger Zuordnung von Blöcken zu CPUs lange Wartezeiten an den Barriers entstehen. Die ursprüngliche blockweise Aufteilung (d.h. q=1..4 für CPU 1 usw.) erwies sich hier als besonders ungünstig. Eine deutliche Verbesserung brachte eine zyklische Verteilung (q=1 an CPU 1, q=2 an CPU 2, ...); der Speedup bei 5 CPUs betrug 2. Der Unterschied zum Idealwert 2.8 ist auf das immer noch vorhandene Last-Ungleichgewicht zurückzuführen, das man mit dem CXpa deutlich erkennen kann (Bild 7).
Vor allem die Threads 0 und 4 sind schneller fertig und haben daher entsprechend große Anteile für wait_barrier.
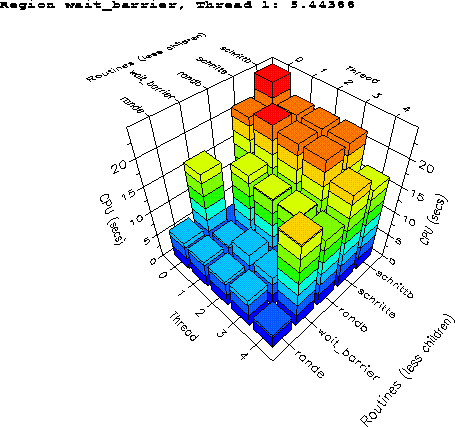
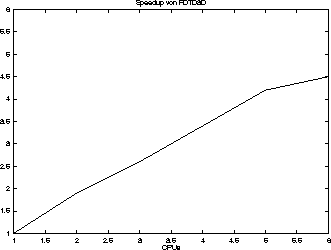
Die tatsächlich interessierenden großen Modelle haben zwei Vorteile: Zum einen ist die Zahl der Blöcke größer, so daß sich einfach aufgrund der Statistik eine bessere Lastverteilung einstellen sollte. Zum anderen ist der CPU-Anteil der betrachteten Routinen - abhängig vom Modell - noch deutlich höher, der skalare Anteil sinkt. Entsprechende Messungen zeigen tatsächlich für die größeren Modelle einen deutlich besseren Parallelisierungs-Gewinn. So liegt etwa der Speedup bei einem Modell mit 270 Blöcken und einer skalaren Laufzeit von knapp 5 Stunden auf 6 CPUs bei 4.5 (s. Bild 8)
In einem nächsten Schritt sollte man sich den übrig gebliebenen ``skalaren'' Anteil genauer ansehen und auf mögliches Parallelisierungs-Potential abklopfen. Außerdem lohnt auch das Lastverteilungsverhalten eine nähere Untersuchung.
Rodrigo Tupynamba (AB Elektrotechnik III) und Peter Junglas (Rechenzentrum), Tel.: 3193